Introduction
Engineering leaders prioritize system resilience as the cornerstone of digital business success in the current technological climate. Practitioners who seek to dominate this domain often choose the Certified Site Reliability Professional designation to validate their high-scale operational expertise. This program, hosted by SreSchool, provides the technical framework necessary to transition from traditional maintenance to advanced platform engineering. This guide offers a comprehensive breakdown of the curriculum, helping professionals navigate the evolving requirements of DevOps and cloud-native environments. By following this roadmap, engineers gain the clarity required to make strategic career moves that align with global industry standards.
What is the Certified Site Reliability Professional?
The Certified Site Reliability Professional acts as a rigorous standard for engineers who apply software engineering methodologies to infrastructure challenges. This program moves beyond simple theoretical knowledge by demanding a deep understanding of production-grade systems and automated recovery protocols. It exists to bridge the gap between building a product and ensuring that product remains available under extreme stress. Engineers who earn this credential demonstrate that they can manage complex microservices with the same precision used in feature development. The curriculum aligns with modern enterprise workflows, focusing on the elimination of manual effort through sophisticated code-driven automation.
Who Should Pursue Certified Site Reliability Professional?
Software engineers who want to influence the entire lifecycle of their applications find immense value in this reliability-focused track. Current DevOps practitioners, cloud architects, and security professionals use this certification to formalize their experience with high-availability distributed systems. Even beginners with a strong coding foundation use the foundational level to enter the specialized field of platform engineering. Technical leaders and engineering managers pursue this knowledge to build resilient teams that prioritize data-driven operational decisions. The program holds massive relevance for the Indian tech market and global enterprises that require 24/7 uptime for their digital assets.
Why Certified Site Reliability Professional is Valuable
Market demand for reliability experts continues to outpace the supply of qualified engineers as companies migrate to complex cloud-native architectures. This certification ensures that your skills remain relevant despite the rapid turnover of specific tools or cloud provider features. By focusing on fundamental principles like observability and error budgets, professionals build a career foundation that survives industry shifts. Enterprises reward this expertise because it directly reduces the massive financial costs associated with system downtime. Ultimately, this credential offers a significant return on investment by positioning you for high-impact roles in the world’s most innovative technology organizations.
Certified Site Reliability Professional Certification Overview
It utilizes a multi-tiered assessment approach that tests both conceptual understanding and practical troubleshooting capabilities. Ownership of the curriculum rests with industry practitioners who ensure the content reflects the actual challenges faced in modern production environments. The structure allows candidates to progress from basic principles to advanced architectural specializations at their own pace. This formal framework provides a transparent way for employers to verify the technical competency of their engineering staff.
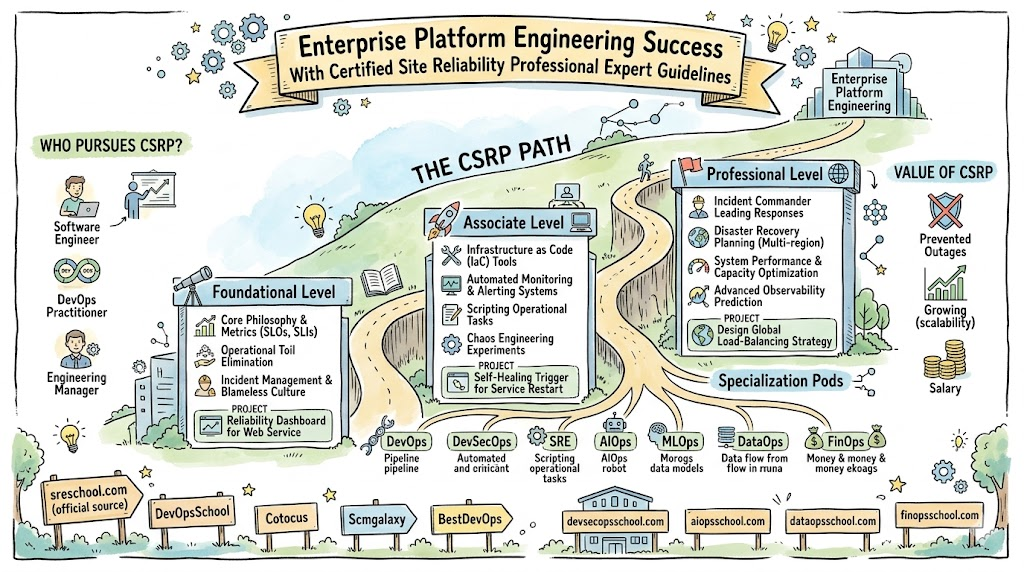
Certified Site Reliability Professional Certification Tracks & Levels
The program offers a logical progression through Foundational, Associate, and Professional levels to suit various career stages. Specialized tracks allow engineers to dive deep into niche areas such as FinOps, DevSecOps, or DataOps depending on their specific professional interests. The Foundational level establishes the core vocabulary, while the Associate level focuses on the practical implementation of monitoring and incident response. Professionals who reach the Advanced level master the art of chaos engineering and global traffic management. This tiered system ensures that every engineer finds a starting point that matches their current experience while providing a clear path for future growth.
Complete Certified Site Reliability Professional Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| SRE Core | Foundational | Beginners/Junior Devs | Basic Linux/Scripting | SLIs, SLOs, Toil | 1 |
| SRE Core | Associate | Mid-Level DevOps | 1+ Year Experience | Observability, Incidents | 2 |
| SRE Architecture | Professional | Senior Engineers | 3+ Years Experience | Chaos Eng, Scaling | 3 |
| FinOps Track | Specialty | Cloud Architects | Cloud Fundamentals | Cloud Cost Management | Optional |
| DevSecOps Track | Specialty | Security Engineers | Security Basics | Automated Compliance | Optional |
| DataOps Track | Specialty | Data Engineers | Data Pipeline Basics | Data Reliability | Optional |
Detailed Guide for Each Certified Site Reliability Professional Certification
Foundational Level
Certified Site Reliability Professional – Foundational
What it is
This certification validates a candidate’s grasp of the core SRE philosophy and basic reliability metrics. It ensures that the practitioner understands the difference between traditional operations and a software-led approach to system health.
Who should take it
Aspiring SREs, computer science students, and non-technical managers should pursue this level to build a common language. It serves as the ideal entry point for anyone entering the DevOps or cloud-native ecosystem.
Skills you’ll gain
- Defining Service Level Indicators (SLIs) and Service Level Objectives (SLOs).
- Quantifying “Toil” and identifying opportunities for automation.
- Understanding the role of Error Budgets in the development lifecycle.
- Interpreting basic system health data from monitoring dashboards.
Real-world projects you should be able to do
- Draft a basic reliability report for a small-scale web application.
- Audit a manual workflow to identify three repetitive tasks for automation.
- Set up a basic uptime monitoring check using an open-source tool.
Preparation plan
- 7–14 days: Review the SRE handbook and official study guides from the portal.
- 30 days: Practice calculating error budgets for hypothetical service scenarios.
- 60 days: Implement basic monitoring for a personal project to track availability.
Common mistakes
- Confusing Service Level Agreements (legal) with technical SLOs.
- Attempting to automate a broken process before understanding the manual steps.
Best next certification after this
- Same-track option: Certified Site Reliability Professional – Associate.
- Cross-track option: DevOps Foundation.
- Leadership option: Technical Lead Essentials.
Associate Level
Certified Site Reliability Professional – Associate
What it is
The Associate level marks the transition into hands-on implementation of reliability engineering practices. It confirms that the engineer can manage production incidents and build robust observability pipelines.
Who should take it
Mid-level software engineers and DevOps practitioners with at least one year of experience should target this level. It suits those who handle on-call duties or manage cloud-based infrastructure daily.
Skills you’ll gain
- Configuring advanced observability using metrics, logs, and traces.
- Executing structured incident response and communication protocols.
- Writing automated scripts to resolve recurring system failures.
- Leading blameless post-mortems to improve organizational resilience.
Real-world projects you should be able to do
- Deploy a full-stack observability suite for a microservices cluster.
- Design an automated on-call rotation and alerting policy.
- Resolve a simulated high-priority production outage within a lab environment.
Preparation plan
- 7–14 days: Deep dive into monitoring tools like Prometheus and Grafana.
- 30 days: Practice incident management simulations and post-mortem writing.
- 60 days: Audit a production-like environment for observability gaps.
Common mistakes
- Setting up too many alerts, which leads to damaging alert fatigue.
- Failing to document the root cause during the high-pressure triage phase.
Best next certification after this
- Same-track option: Certified Site Reliability Professional – Professional.
- Cross-track option: Certified DevSecOps Specialist.
- Leadership option: SRE Manager Training.
Professional/Specialty Level
Certified Site Reliability Professional – Professional
What it is
This certification represents the pinnacle of reliability engineering, focusing on architecting systems for catastrophic failure. It validates the ability to perform chaos engineering and manage global-scale traffic.
Who should take it
Senior engineers and architects with over three years of production experience should pursue this designation. It is designed for those who own the uptime of mission-critical enterprise platforms.
Skills you’ll gain
- Designing and executing controlled chaos engineering experiments.
- Architecting multi-region failover and disaster recovery strategies.
- Managing complex capacity planning for rapid growth scenarios.
- Optimizing distributed systems for latency and high throughput.
Real-world projects you should be able to do
- Execute a “Game Day” to test system resilience under simulated failure.
- Automate a multi-cloud failover process for a database tier.
- Perform a deep-dive performance tune-up on a high-traffic microservice.
Preparation plan
- 7–14 days: Study advanced architectural patterns for distributed resilience.
- 30 days: Build and test a chaos engineering pipeline in a staging environment.
- 60 days: Lead a large-scale reliability overhaul for a production system.
Common mistakes
- Over-engineering solutions for failures that carry low business risk.
- Neglecting the cultural shift required for successful chaos engineering.
Best next certification after this
- Same-track option: Distinguished Reliability Architect.
- Cross-track option: Certified FinOps Professional.
- Leadership option: Engineering Director / CTO Track.
Choose Your Learning Path
DevOps Path
Engineers on the DevOps path focus on the seamless integration of development and operations through automation. They prioritize the speed of delivery while ensuring that every release meets a minimum stability threshold. This path focuses heavily on CI/CD pipelines and infrastructure as code to maintain consistency across various environments. Practitioners here act as the bridge that allows features to reach production safely and frequently.
DevSecOps Path
The DevSecOps path integrates security checks directly into the automated reliability lifecycle. Professionals ensure that every deployment undergoes rigorous security scanning without slowing down the release cycle. They treat security as a fundamental aspect of system uptime, protecting against both technical failure and malicious attacks. This path is essential for engineers working in highly regulated industries like finance or healthcare.
SRE Path
The SRE path emphasizes a pure software engineering approach to managing production systems. These specialists focus on observability, error budgets, and the systematic reduction of manual toil. They aim to build self-healing systems that require minimal human intervention to maintain high availability. This path suits those who enjoy deep-diving into system internals and optimizing distributed architectures.
AIOps Path
AIOps specialists use artificial intelligence to manage the massive influx of telemetry data from modern systems. They build models that can predict outages and automate complex troubleshooting steps before a human even notices an issue. This path represents the future of operations, where machine learning handles the complexity of hyperscale environments. Engineers here bridge the gap between data science and system administration.
MLOps Path
MLOps professionals apply reliability principles to the specific lifecycle of machine learning models. They ensure that training pipelines, model deployments, and inference services remain stable and performant. This path addresses unique challenges like data drift and model decay that traditional SRE practices might miss. As AI becomes core to every product, MLOps specialists ensure these intelligence layers scale reliably.
DataOps Path
DataOps focuses on the reliability and speed of data flows throughout an organization. Engineers on this path ensure that data pipelines remain available and that the data itself remains accurate for downstream analytics. They apply SRE concepts to manage database clusters and real-time processing engines like Spark or Flink. This path is critical for data-driven enterprises that rely on real-time insights for decision-making.
FinOps Path
FinOps practitioners manage the financial health of cloud infrastructure by correlating costs with engineering performance. They help organizations optimize their cloud spend through right-sizing and strategic resource allocation without sacrificing system reliability. This path requires a unique blend of technical expertise and financial acumen. Professionals here ensure that the cloud-native transition remains profitable and sustainable for the business.
Role → Recommended Certified Site Reliability Professional Certifications
| Role | Recommended Certifications |
| DevOps Engineer | Foundational, Associate, DevSecOps Specialty |
| SRE | Foundational, Associate, Professional |
| Platform Engineer | Associate, Professional, FinOps Specialty |
| Cloud Engineer | Foundational, Associate, FinOps Specialty |
| Security Engineer | Foundational, DevSecOps Specialty |
| Data Engineer | Foundational, DataOps Specialty |
| FinOps Practitioner | Foundational, FinOps Specialty |
| Engineering Manager | Foundational, SRE Leadership Path |
Next Certifications to Take After Certified Site Reliability Professional
Same Track Progression
Professionals who complete the Professional level often move toward specialized cloud architect designations from providers like AWS or Google Cloud. These certifications complement the SRE mindset by adding deep platform-specific knowledge. You should also consider advanced training in high-performance computing or networking to further refine your infrastructure expertise. Staying within the same track ensures you remain a leading authority in the reliability engineering domain.
Cross-Track Expansion
Broadening your expertise into security or finance provides a more holistic view of the enterprise engineering landscape. Earning a DevSecOps credential allows you to address the growing intersection of reliability and cybersecurity. Alternatively, a FinOps certification proves that you can manage large-scale budgets alongside large-scale systems. This expansion makes you a versatile asset capable of solving multifaceted business problems.
Leadership & Management Track
Engineers looking to move into people management should pursue certifications in technical leadership or engineering management. These programs focus on team dynamics, strategic planning, and the cultural aspects of SRE. Moving into leadership requires you to scale reliability practices across multiple teams rather than just managing a single system. This track prepares you for high-level roles like Director of Reliability or CTO.
Training & Certification Support Providers for Certified Site Reliability Professional
- DevOpsSchool
DevOpsSchool offers a comprehensive training ecosystem that prioritizes practical, lab-based learning for SRE and DevOps professionals. They provide a structured curriculum that covers everything from foundational automation to advanced cloud-native orchestration. Their trainers bring real-world industry experience into the classroom, ensuring that every student understands how to apply reliability principles in a high-pressure production environment. Candidates benefit from their extensive library of resources and dedicated support for passing professional-level certifications. - Cotocus
Cotocus specializes in providing high-end technical consulting and specialized training for enterprise engineering teams. They focus heavily on the architectural patterns required to maintain high availability in multi-cloud and hybrid environments. Their training approach for the SRE certification emphasizes complex failure scenarios and the strategic implementation of observability. Professionals who choose this provider gain deep insights into how the world’s largest companies manage their digital infrastructure at scale. - Scmgalaxy
Scmgalaxy acts as a major community hub and resource provider for software configuration management and DevOps practitioners. They offer a vast array of tutorials, blogs, and specialized training programs designed to help engineers master the art of reliability. Their support for the SRE track includes a focus on the cultural shifts necessary to implement SRE practices successfully. Engineers value their community-driven approach and the practical, down-to-earth guidance provided by their veteran instructors. - BestDevOps
BestDevOps delivers high-quality, curated training programs that focus on the most in-demand skills in the current engineering market. They provide a streamlined path to certification by focusing on the core competencies required for modern site reliability engineering. Their materials are updated frequently to reflect the latest changes in the cloud-native landscape, ensuring that students learn current best practices. Candidates appreciate their clear instructional style and the strong emphasis on job-ready technical skills. - devsecopsschool.com
devsecopsschool.com provides specialized training that bridges the gap between security and site reliability engineering. They teach candidates how to automate security checks within the reliability pipeline, ensuring that every deployment remains secure and stable. Their curriculum is essential for SREs who want to specialize in protecting mission-critical infrastructure from cyber threats. Students gain hands-on experience with the latest security automation tools used in top-tier technology firms. - sreschool.com
sreschool.com serves as the primary authority and official host for the Certified Site Reliability Professional program. Because they manage the certification standards, their training materials offer the most direct path to passing the exam. They provide an immersive learning experience that includes interactive labs, expert-led webinars, and a global community of reliability practitioners. Choosing this provider ensures that you are learning the most current and authoritative version of the SRE curriculum. - aiopsschool.com
aiopsschool.com focuses on the next generation of operations by teaching engineers how to integrate artificial intelligence into their SRE workflows. Their training covers the use of machine learning for predictive maintenance and automated incident resolution. Professionals who want to stay ahead of the curve in hyperscale management find their curriculum indispensable. They offer a unique blend of data science concepts and practical systems engineering that is rare in the training market. - dataopsschool.com
dataopsschool.com addresses the unique reliability challenges of managing massive, high-velocity data pipelines. They teach engineers how to apply SRE principles to ensure data integrity and availability across the entire enterprise. Their courses cover the management of distributed databases, real-time streaming engines, and big data platforms. Students learn how to build self-healing data systems that can scale to meet the needs of the modern data-driven economy. - finopsschool.com
finopsschool.com provides the specialized training required to master the financial aspects of cloud engineering. They teach professionals how to correlate every engineering decision with its impact on the company’s cloud bill. Their curriculum focuses on cost optimization strategies that do not compromise on performance or reliability. This training is essential for SREs and cloud architects who want to have a seat at the table when business strategy is discussed.
Frequently Asked Questions
- How much coding experience do I need for the Associate level?
Candidates should possess intermediate skills in a language like Python or Go to successfully automate complex operational tasks. - Does the program focus on a specific cloud provider?
The certification remains cloud-agnostic, teaching principles that apply equally to AWS, Google Cloud, Azure, and on-premise environments. - What is the typical timeframe for completing the professional level?
Most experienced engineers spend between 60 and 90 days preparing for the professional exam to ensure they master the architectural concepts. - Is there a prerequisite for the foundational certification?
No, the foundational level is open to everyone, although a basic understanding of computer systems and Linux will help significantly. - Does the exam include a practical lab component?
Yes, the Associate and Professional levels require you to solve real-world problems in a live, proctored environment. - How long does the certification remain valid after passing?
The certification typically remains valid for two years, after which you must renew it or advance to a higher tier. - Can I skip the foundational level and go straight to Associate?
Yes, if you have sufficient industry experience, you can jump directly to the Associate level, though the foundational concepts are highly recommended. - Are there any specific hardware requirements for the training?
No, most support providers offer cloud-based lab environments that you can access through a standard web browser. - Does the program cover Kubernetes and container orchestration?
Yes, the curriculum features Kubernetes heavily at the Associate and Professional levels as the industry standard for microservices management. - What is the passing score for the certification exams?
The passing threshold generally sits at 70%, though this can vary slightly based on the specific level and version of the exam. - Are the study materials included in the certification fee?
This depends on the provider you choose, but SreSchool typically bundles core study guides with the exam registration. - Can I retake the exam if I do not pass on the first attempt?
Yes, SreSchool allows for retakes after a mandatory waiting period, during which you should review the feedback from your previous attempt.
FAQs on Certified Site Reliability Professional
- How does the curriculum address the cultural challenges of implementing SRE?
The program moves beyond technical tools to teach engineers how to foster a “Blameless Culture” within their organizations. You learn how to lead post-mortems that focus on system improvement rather than finding someone to fault for an outage. This cultural training ensures that the reliability practices you implement actually stick and lead to long-term organizational change. By mastering these soft skills, you become a leader who can guide teams through the difficult transition from legacy operations to modern SRE. - Does the certification provide specific guidance on Error Budget policies?
Yes, the course teaches you how to negotiate and implement Error Budget policies that both developers and operations teams can agree upon. You learn the mathematical models used to determine when a release should be halted due to stability concerns. This practical training helps you resolve the classic conflict between the need for new features and the requirement for system uptime. Mastering this balance is what makes an SRE indispensable to a product-focused engineering organization. - What role does Chaos Engineering play in the Professional tier?
Chaos Engineering is treated as a proactive testing methodology rather than a way to cause random damage. The professional level teaches you how to design controlled experiments that inject failure into a system to verify its recovery logic. You learn how to set “blast radii” to ensure that your experiments do not accidentally cause a widespread production outage. This high-level skill allows you to prove your system’s resilience before a real-world disaster occurs. - How are the specialties like FinOps integrated with the core SRE tracks?
The specialties are designed as “force multipliers” that add a specific lens to your existing reliability knowledge. For instance, the FinOps specialty teaches you how to achieve your SLOs using the most cost-effective resource configurations possible. You learn to treat “cost” as a fundamental system constraint, much like latency or throughput. This integration ensures that your engineering decisions align with the financial realities of the business, making your role more strategic. - Does the program cover the implementation of advanced observability stacks?
The Associate and Professional levels dive deep into the differences between simple monitoring and true observability. You learn how to instrument your applications to provide high-cardinality data that makes debugging complex microservices possible. The curriculum covers the setup of distributed tracing and the intelligent aggregation of logs to find “the needle in the haystack.” This knowledge ensures you can solve the “unknown-unknowns” that plague modern distributed architectures. - How does the certification prepare engineers for on-call duty?
The program provides a framework for managing on-call rotations that minimize burnout and maximize response efficiency. You learn how to build “runbooks” that allow any engineer to resolve an issue quickly without deep prior knowledge of the specific service. The training emphasizes the creation of actionable alerts that only trigger when user-facing SLOs are at risk. This approach turns on-call from a dreaded chore into a manageable and data-driven engineering task. - Is the curriculum updated to reflect the latest cloud-native trends?
SreSchool employs a committee of active practitioners who review and update the exam objectives twice a year. This ensures that the certification remains relevant to the latest shifts in container orchestration, serverless computing, and infrastructure as code. You won’t find yourself studying legacy technologies that the industry has already moved past. This commitment to currency makes the Certified Site Reliability Professional one of the most respected credentials in the DevOps space. - What is the significance of the “Four Golden Signals” in the exam?
The exam tests your ability to monitor Latency, Traffic, Errors, and Saturation as the primary indicators of system health. You learn how to set appropriate thresholds for each of these signals across different types of services. The curriculum teaches you that if you can only monitor four things, these should be them. Mastering the Four Golden Signals provides a simplified yet powerful way to maintain visibility into even the most complex production environments.
Final Thoughts: Is Certified Site Reliability Professional Worth It?
Choosing a professional path in reliability engineering requires a significant commitment to both software excellence and operational rigor. The Certified Site Reliability Professional designation provides the structure and validation needed to excel in this demanding field. By focusing on the principles that keep the world’s most critical systems running, you ensure your place at the forefront of the technology industry. This certification proves that you possess the skills to transform chaotic manual operations into a disciplined engineering practice. If you aim to lead the next generation of platform engineering, this roadmap offers the most direct and effective journey to that goal.